놓치고 있는 지표들
AWS 환경에서는 VPC Flow Logs를 통해 엔드포인트 별 데이터 전송량을 볼 수 있습니다. 특히 AWS Flow Logs로 엔드포인트의 리전과 가용 영역 정보를 알 수 있어, 네트워크 전송량 과금을 모니터링할 때 유용합니다.
그런데 TCP 계층의 성능 모니터링은 어떻게 해야 할까요? TCP 계층에서는 패킷 유실, out-of-order delivery로 인한 latency 증가, throughput 저하 등의 성능 문제가 발생할 수 있습니다. 하지만 이를 모니터링하는 것은 쉽지 않은데, 이때 필요한 것이 eBPF입니다. 또, Cloudflare의 ebpf-exporter를 사용하면 eBPF 프로그램을 쉽게 prometheus exporter로 만들 수 있습니다.
TCP 성능 지표
eBPF로 트레이싱 가능한 TCP 성능 지표들은 매우 많습니다. 이번에는 tcp_sock 구조체를 트레이싱하는 것만 다루겠습니다. 다양한 성능 지표들이 한 구조체 안에 모여있어 쉽게 시작할 수 있기 때문입니다.
커널 5.10 버전에서는 tcp_sock 구조체에 아래 필드들이 있습니다.
bytes_received
해당 소켓이 받은 총 바이트 수bytes_sent
해당 소켓이 보낸 총 바이트 수total_retrans
해당 소켓에서 발생한 총 재전송 수lost
해당 소켓에서 패킷 유실을 감지한 총 횟수srtt_us
해당 소켓의 smoothed rount trip time
여기서 total_retrans와 lost는 서로 다르다는 것을 유의해야 합니다. Tail Loss Probe라는 혼잡 감지 알고리즘은 꼭 네트워크에 혼잡이 있지 않아도 세그먼트를 재전송하기도 합니다.
따라서 total_retrans 보다는 lost 필드가 네트워크 성능에 더 직접적으로 관련이 있습니다. lost가 많다는 것은 해당 네트워크 구간이 자주 혼잡했다는 의미입니다.
커널 6.7 버전에서는 tcp_sock 구조체에 RTO 관련 필드들이 추가되었습니다.
total_rtototal_rto_recoveriestotal_rto_time
RTO란 RTO 타이머 기반으로 네트워크 혼잡을 감지한 경우를 말합니다. 리눅스에서는 현재 최소 RTO 타이머가 200ms이기 때문에, RTO가 발생했다는 것은 어플리케이션에 매우 큰 응답 저하가 발생했다는 의미입니다. 따라서 주의 깊게 봐야 할 지표입니다.
하지만 이번에 사용할 테스트 환경은 커널 5.10 버전이므로, 위 5개 지표만 수집해 보겠습니다.
트레이싱 포인트
tcp_sock 구조체를 감시하기 위해서는 TCP 관련 커널 함수를 트레이싱 해야 합니다. 트레이싱 포인트 선택지가 몇 가지 있습니다.
첫째로, tcp_rcv_established 함수를 트레이싱 할 수도 있습니다. 이 함수는 ESTABLISHED 상태에서 세그먼트를 수신할 때 실행됩니다. 이 함수의 첫 번째 인자가 sock 구조체이기 때문에 tcp_sock 정보를 쉽게 접근할 수 있습니다. 세그먼트 수신은 매우 활발하게 발생하는 활동이므로 소켓의 최신 정보를 빠르게 받을 수 있다는 장점이 있지만, 그만큼 오버헤드가 커집니다.
다른 선택지는 inet_sock_set_state 함수를 트레이싱하는 것입니다. 이 함수는 소켓의 상태가 변할 때 실행됩니다. 이 함수의 인자에는 sock 구조체와 소켓의 신규 상태 newstate가 있습니다. newstate가 TCP_CLOSE일 때 데이터를 기록하면 소켓이 닫힐 때마다 성능 지표들을 쓰게 할 수 있습니다. 지속 커넥션을 사용하는 환경에서는 tcp_rcv_established 보다는 소켓 지표 정보가 느리게 갱신되겠지만, 호출 빈도가 훨씬 적어 오버헤드가 적다는 장점이 있습니다. 심지어 이 함수는 tracepoint도 있기 때문에 오버헤드를 더 줄일 수 있습니다.
이 예제에서는 inet_sock_set_state 함수를 트레이싱 해보겠습니다.
구현
eBPF 코드 작성
우선 eBPF 맵의 키가 될 구조체들을 정의해 줍니다.
#define AF_INET 2
#define AF_INET6 10
#define MAX_ENTRIES 8192
#define MAX_BUCKET_SLOT 11
struct ipv4_key_t {
u32 saddr;
u32 saddr_ns;
u32 saddr_az;
u32 daddr;
u32 daddr_ns;
u32 daddr_az;
};
struct ipv4_bucket_key_t {
u32 saddr;
u32 saddr_ns;
u32 saddr_az;
u32 daddr;
u32 daddr_ns;
u32 daddr_az;
u64 bucket;
};
키의 각 필드들은 prometheus의 label이 될 겁니다. IP 주소, 해당 IP 주소가 속해있는 kubernetes namespace, 그리고 AWS 가용 영역 정보로 label을 만들겠습니다.
srtt 지표는 histogram으로 저장하기 위해 bucket 필드가 있는 ipv4_bucket_key_t 구조체를 따로 정의했습니다.
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, MAX_ENTRIES * (MAX_BUCKET_SLOT + 2));
__type(key, struct ipv4_bucket_key_t);
__type(value, u64);
} tcp_ipv4_srtt_usec SEC(".maps");
struct {
__uint(type, BPF_MAP_TYPE_LRU_HASH);
__uint(max_entries, MAX_ENTRIES);
__type(key, struct ipv4_key_t);
__type(value, u64);
} tcp_ipv4_bytes_sent SEC(".maps");
struct {
__uint(type, BPF_MAP_TYPE_LRU_HASH);
__uint(max_entries, MAX_ENTRIES);
__type(key, struct ipv4_key_t);
__type(value, u64);
} tcp_ipv4_bytes_recv SEC(".maps");
struct {
__uint(type, BPF_MAP_TYPE_LRU_HASH);
__uint(max_entries, MAX_ENTRIES);
__type(key, struct ipv4_key_t);
__type(value, u64);
} tcp_ipv4_retrans SEC(".maps");
struct {
__uint(type, BPF_MAP_TYPE_LRU_HASH);
__uint(max_entries, MAX_ENTRIES);
__type(key, struct ipv4_key_t);
__type(value, u64);
} tcp_ipv4_lost SEC(".maps");
그다음은 eBPF 맵을 정의합니다. eBPF 맵은 각각 prometheus 매트릭이 됩니다. 여기서는 tcp_ipv4_srtt_usec, tcp_ipv4_bytes_sent, tcp_ipv4_bytes_recv, tcp_ipv4_retrans, tcp_ipv4_lost를 매트릭으로 노출시키겠습니다.
SEC("tp_btf/inet_sock_set_state")
int BPF_PROG(inet_sock_set_state, struct sock *sk, int oldstate, int newstate)
{
if (newstate != BPF_TCP_CLOSE)
return 0;
struct tcp_sock *tp = (struct tcp_sock *)sk;
struct ipv4_key_t key = {};
struct ipv4_bucket_key_t bucket_key = {};
switch (sk->__sk_common.skc_family) {
case AF_INET:
bucket_key.saddr_az = bucket_key.saddr_ns = bucket_key.saddr = key.saddr_az = key.saddr_ns = key.saddr = sk->__sk_common.skc_rcv_saddr;
bucket_key.daddr_az = bucket_key.daddr_ns = bucket_key.daddr = key.daddr_az = key.daddr_ns = key.daddr = sk->__sk_common.skc_daddr;
increment_map(&tcp_ipv4_bytes_sent, &key, BPF_CORE_READ(tp, bytes_sent));
increment_map(&tcp_ipv4_bytes_recv, &key, BPF_CORE_READ(tp, bytes_received));
increment_map(&tcp_ipv4_retrans, &key, BPF_CORE_READ(tp, total_retrans));
increment_map(&tcp_ipv4_lost, &key, BPF_CORE_READ(tp, lost));
increment_exp2_histogram(&tcp_ipv4_srtt_usec, bucket_key, BPF_CORE_READ(tp, srtt_us) / 1000, MAX_BUCKET_SLOT);
break;
case AF_INET6:
break;
}
return 0;
}
이제 inet_sock_set_state tracepoint를 생성해 줍니다. newstate가 TCP_CLOSE일 때만 소켓 정보를 eBPF 맵에 저장하도록 했습니다.
saddr_az, saddr_ns, saddr 등의 필드에 모두 IP 주소를 저장하고 있는 것을 보실 수 있습니다. 우선은 모두 IP 주소로 저장한 다음, 유저 영역의 go 프로그램에서 이를 쿠버네티스 메타데이터로 변환할 예정입니다.
Pod Decoder 구현
eBPF 맵의 키를 적절히 prometheus label로 변환시키기 위해서는 ebpf-exporter의 decorder를 사용해야 합니다. ebpf-exporter는 기본적으로 inet_ip, string, syscalls 등 여러 종류의 decoder들을 지원합니다.
하지만 pod의 IP 주소를 가지고 pod가 실행된 namespace와 AWS 가용 영역을 가져오는 decoder는 없기에 구현이 필요합니다. 아래 decoder는 IP 주소를 입력받아 쿠버네티스 API를 통해 해당 IP 주소를 가진 pod와 그에 맞는 node를 조회하고 데이터를 가져옵니다.
package decoder
import (
"context"
v1 "k8s.io/api/core/v1"
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
"k8s.io/client-go/kubernetes"
"k8s.io/client-go/rest"
"net"
"github.com/cloudflare/ebpf_exporter/v2/config"
)
type PodNamespace struct{}
type PodAZ struct{}
func getClientSet() *kubernetes.Clientset {
clusterConfig, err := rest.InClusterConfig()
if err != nil {
return nil
}
clientset, err := kubernetes.NewForConfig(clusterConfig)
if err != nil {
return nil
}
return clientset
}
func getPodByIP(clientset *kubernetes.Clientset, ip string) *v1.Pod {
listOptions := metav1.ListOptions{
FieldSelector: "status.podIP=" + ip,
}
pods, err := clientset.CoreV1().Pods("").List(context.TODO(), listOptions)
if err != nil || len(pods.Items) != 1 {
return nil
}
return &pods.Items[0]
}
func getNodeByName(clientset *kubernetes.Clientset, name string) *v1.Node {
listOptions := metav1.ListOptions{
FieldSelector: "metadata.name=" + name,
}
nodes, err := clientset.CoreV1().Nodes().List(context.TODO(), listOptions)
if err != nil || len(nodes.Items) != 1 {
return nil
}
return &nodes.Items[0]
}
func (p *PodNamespace) Decode(in []byte, _ config.Decoder) ([]byte, error) {
ip := net.IP(in).String()
clientset := getClientSet()
if clientset == nil {
return []byte("unknown"), nil
}
pod := getPodByIP(clientset, ip)
if pod == nil {
return []byte("unknown"), nil
}
return []byte(pod.GetNamespace()), nil
}
func (p *PodAZ) Decode(in []byte, _ config.Decoder) ([]byte, error) {
ip := net.IP(in).String()
clientset := getClientSet()
if clientset == nil {
return []byte("unknown"), nil
}
pod := getPodByIP(clientset, ip)
if pod == nil {
return []byte("unknown"), nil
}
nodeName := pod.Spec.NodeName
node := getNodeByName(clientset, nodeName)
if node == nil {
return []byte("unknown"), nil
}
az, ok := node.Labels["topology.kubernetes.io/zone"]
if !ok {
return []byte("unknown"), nil
}
return []byte(az), nil
}
그리고 decoder/decoders.go에 구현한 decoder를 등록해 줍니다.
return &Set{
decoders: map[string]Decoder{
// ...
"pod_namespace": &PodNamespace{},
"pod_az": &PodAZ{},
},
cache: map[string]map[string][]string{},
}, nil
이제 tcp-life.yaml 파일을 생성하여 eBPF 맵 키의 필드들에 적절한 decoder를 선언해 줍니다.
metrics:
counters:
- name: tcp_ipv4_bytes_sent
help: Total Bytes sent of IPv4 TCP endpoint
labels:
- name: local_ip
size: 4
decoders:
- name: inet_ip
- name: local_namespace
size: 4
decoders:
- name: pod_namespace
- name: local_az
size: 4
decoders:
- name: pod_az
- name: peer_ip
size: 4
decoders:
- name: inet_ip
- name: peer_namespace
size: 4
decoders:
- name: pod_namespace
- name: peer_az
size: 4
decoders:
- name: pod_az
...
모든 코드는 github에서 보실 수 있습니다.
결과
지금까지 만든 ebpf-exporter를 사용하면 아래와 같은 대시보드를 구성할 수 있습니다.
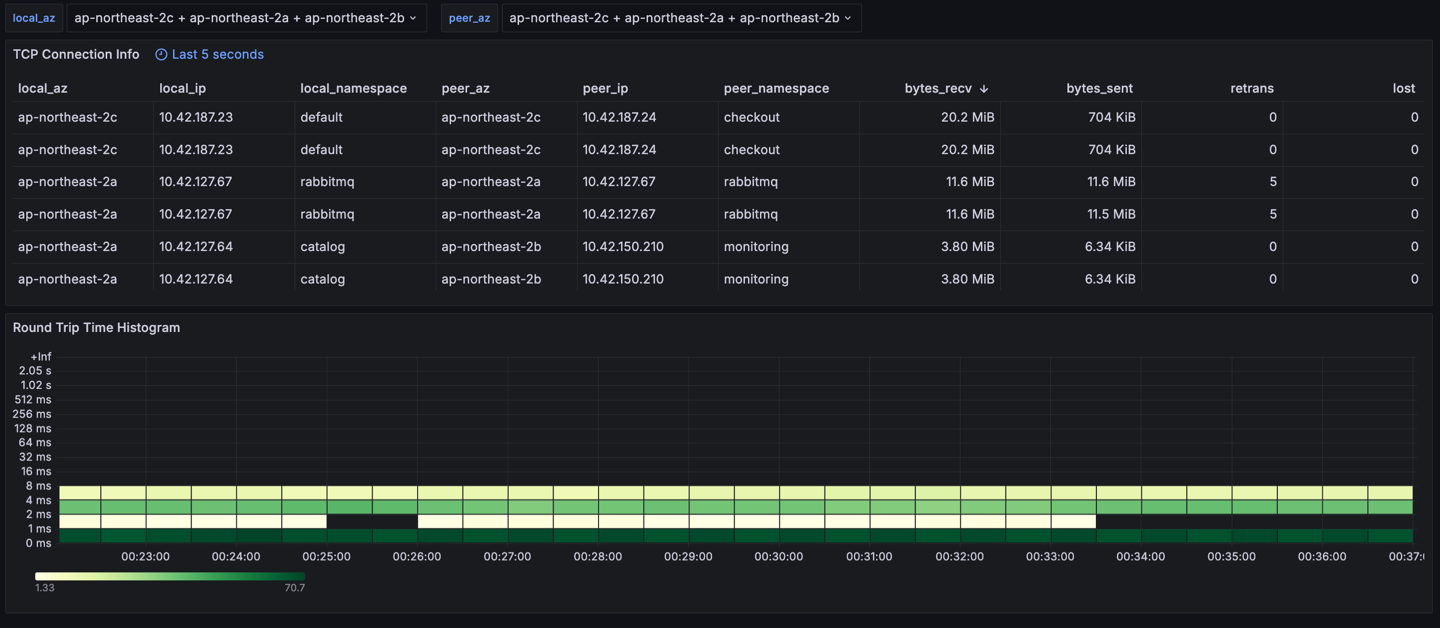
이제 pod 간 통신의 디테일한 통계 정보를 알 수 있습니다. 위 예시를 보면 다행히 서로 다른 가용 영역 간의 과도한 트래픽은 없고, retrans가 일부 있지만 loss는 모두 0이기 때문에 네트워크 문제도 없음을 알 수 있습니다.
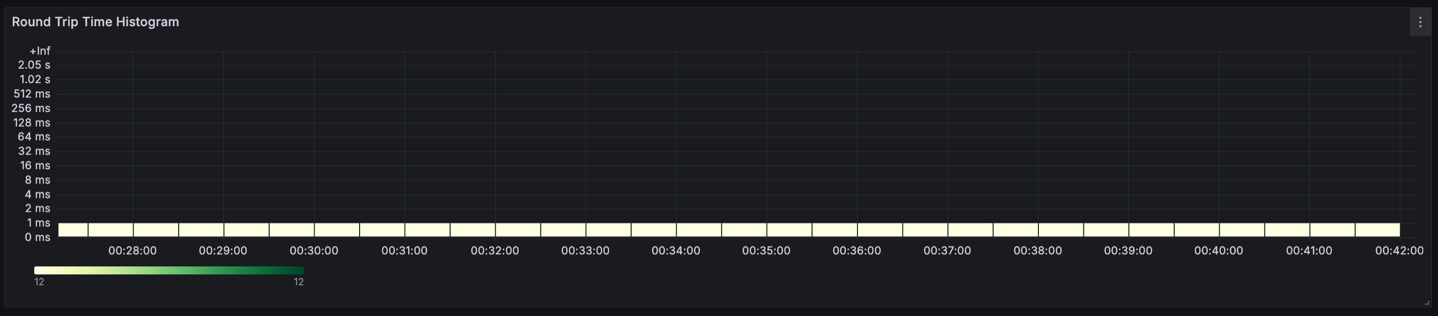
또, 조건 별 round trip time을 분석할 수도 있습니다. 아래 그림은 ap-northeast-2c 내부 통신의 rtt 분포입니다. Rtt가 모두 1ms 미만인 것을 볼 수 있습니다.
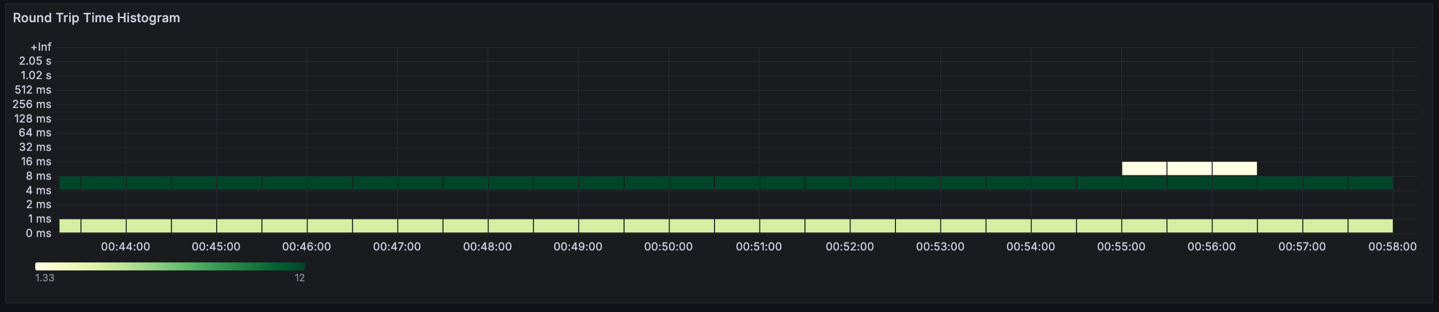
아래 그림은 ap-northeast-2c와 ap-northeast-2b간 통신의 rtt 분포입니다. 대부분은 4ms에서 8ms 사이에 분포하고 있고, 일부는 8ms 이상이 되기도 했습니다.
정리
이렇게 eBPF를 활용하면 Istio나 AWS VPC Flow Logs로는 볼 수 없었던 또다른 네트워크 성능 지표를 관측할 수 있습니다. 또, ebpf-expoter의 커스텀 decoder와 쿠버네티스 API를 활용하면 다양한 쿠버네티스 정보를 prometheus label로 넣을 수도 있습니다.
이번 프로젝트에서는 eBPF를 통해 tcp_sock 구조체의 일부 필드만을 수집했지만 리눅스 네트워크 모니터링 1편과 2편에서 소개드린 주요 커널 함수들(kfree_skb, tcp_retransmit_skb, tcp_set_ca_state 등)을 트레이싱하면 더 자세한 네트워크 성능 모니터링이 가능합니다.