개요
리눅스 네트워크 모니터링 1편에서는 호스트 내에서 드랍되는 패킷을 모니터링하는 방법을 설명드렸습니다. 이번 글에서는 네트워크에서 발생한 문제를 감지하는 방법을 소개드리겠습니다.
이상적으로는 우리가 온전히 제어할 수 있는 데이터센터 내부에서는 패킷 유실 등의 네트워크 문제가 없어야 합니다. 하지만 현실에서는 네트워크 장비의 부하나 오동작으로 인해 네트워크 문제가 발생하고는 합니다.
네트워크 장비에서 패킷 드랍 통계를 모니터링하여 이를 감지할 수 있기도 하지만, 이것 만으로는 어떤 패킷이 버려졌는지 그리고 그로 인해 어떤 서비스가 얼마나 영향을 받았는지는 알기 어렵습니다. 리눅스 호스트에서 모니터링을 한다면 이런 정보도 알 수 있게 됩니다.
리눅스의 TCP 혼잡 제어
네트워크의 문제는 호스트의 TCP 혼잡 제어 동작을 감시하는 것으로 모니터링할 수 있습니다.
혼잡 제어는 데이터 전송자가 네트워크 상태를 예상해가며 데이터 전송량을 조절하는 기능입니다. 네트워크가 여유로워 보이면 전송량을 늘리고, 네트워크가 혼잡해 보이면 전송량을 줄입니다. 리눅스에서는 네트워크 혼잡도에 따른 전송량을 조절하기 위해 소켓 별로 congestion window(cwnd)라는 변수를 관리합니다.
데이터 전송자는 네트워크의 혼잡 여부를 판단하기 위해 여러 기술들을 사용합니다. 예를들어 특정 시간(Retransmission timer, RTO) 이내에 ACK를 받지 못하면 네트워크의 혼잡으로 패킷이 유실되었다고 판단하고 cwnd를 줄이며 패킷을 재전송합니다. 이 방법은 데이터 전송자가 RTO 시간 동안 데이터를 전송하지 못하고 대기하므로 큰 성능 저하가 발생합니다. 따라서 가능한 최후의 수단으로 사용되어야 합니다.
네트워크 혼잡을 더 빠르게 판단하는 방법 중 하나로 duplicate ACK를 감시하는 방법이 있습니다. 데이터의 중간에서 패킷이 유실되었다면 데이터 수신자는 중복된 ACK를 전송합니다. 데이터 전송자는 중복된 ACK를 일정 수 이상 받으면 네트워크에 혼잡이 있다고 판단하고 cwnd를 줄이고 패킷을 재전송합니다.
Duplicate ACK를 통한 감지는 패킷 유실이 데이터의 여러 지점에서 발생했을 때와 데이터의 끝 부분에서 발생했을 때에는 효과적으로 동작하지 못합니다. 이를 개선하기 위해 SACK 및 Tail Loss Probe(TLP) 등의 기술들이 사용됩니다.
네트워크가 혼잡하지 않음에도 불구하고 데이터 전송자가 잘못 판단하고 cwnd를 줄일 수도 있습니다. 예를들어 두 TCP 호스트 사이 네트워크에 equal-cost multi-path(ECMP) 라우팅이 있는데, 네트워크 장비가 ECMP 알고리즘으로 해싱을 사용하지 않고 라운드로빈을 사용한다면 데이터 수신자에게 패킷 순서가 뒤바뀌어 전달될 수 있습니다. 이 경우 네트워크에 혼잡이 있는 건 아니지만 데이터 수신자는 중복된 ACK 혹은 SACK을 응답하게 되며, 데이터 전송자는 이를 잘못 해석하고 네트워크에 혼잡이 있다고 판단할 수 있습니다. 이런 상황을 방지하기 위해 DSACK 등의 정보를 활용하여 줄였던 cwnd를 다시 복구시키기도 합니다.
리눅스에서는 판단한 네트워크 상태를 inet_connection_sock의 icsk_ca_state 변수에 저장합니다. TCP의 혼잡 상태는 아래와 같이 5가지가 존재합니다.
// linux/tcp.h
enum tcp_ca_state {
/*
* Nothing bad has been observed recently.
* No apparent reordering, packet loss, or ECN marks.
*/
TCP_CA_Open = 0,
#define TCPF_CA_Open (1<<TCP_CA_Open)
/*
* The sender enters disordered state when it has received DUPACKs or
* SACKs in the last round of packets sent. This could be due to packet
* loss or reordering but needs further information to confirm packets
* have been lost.
*/
TCP_CA_Disorder = 1,
#define TCPF_CA_Disorder (1<<TCP_CA_Disorder)
/*
* The sender enters Congestion Window Reduction (CWR) state when it
* has received ACKs with ECN-ECE marks, or has experienced congestion
* or packet discard on the sender host (e.g. qdisc).
*/
TCP_CA_CWR = 2,
#define TCPF_CA_CWR (1<<TCP_CA_CWR)
/*
* The sender is in fast recovery and retransmitting lost packets,
* typically triggered by ACK events.
*/
TCP_CA_Recovery = 3,
#define TCPF_CA_Recovery (1<<TCP_CA_Recovery)
/*
* The sender is in loss recovery triggered by retransmission timeout.
*/
TCP_CA_Loss = 4
#define TCPF_CA_Loss (1<<TCP_CA_Loss)
};
TCP_CA_Open
네트워크가 혼잡하지 않다고 판단된 상태입니다.
TCP_CA_Disorder
중복된 ACK 혹은 SACK을 받은 상태입니다. 패킷 순서가 뒤바뀌어 전달됐을 가능성도 있으므로 아직은 네트워크가 혼잡하다고 판단하지 않았습니다.
TCP_CA_CWR
ECN 등으로 네트워크 혼잡을 알게된 상태입니다.
TCP_CA_Recovery
중복된 ACK, SACK, RACK-TLP 등으로 네트워크 혼잡을 빠르게 감지한 상태입니다.
TCP_CA_Loss
RTO를 통해 네트워크 혼잡을 감지한 상태입니다.
이 중 주의깊게 봐야할 상태는 TCP_CA_Loss와 TCP_CA_Recovery입니다. TCP_CA_Loss 상태에 있다는 것은 적어도 RTO 시간 동안 패킷이 전달되지 못하여 응답 지연이 발생했고 cwnd가 크게 줄어들어 throughput 저하가 발생했다는 것이며, TCP_CA_Recovery 상태에 있다는 것은 빠른 재전송을 하여 응답 지연은 눈에 띄지 않을 수 있으나 역시 cwnd가 감소하여 throughput 저하가 발생했다는 것을 의미합니다.
또한 두 상태 모두 네트워크가 혼잡하다는 것을 나타내기에 데이터센터 내부 통신에서 이 두 상태가 발견되었다면 네트워크를 점검해봐야 합니다.
메트릭
이제 TCP의 혼잡 제어 관련 통계를 설명드리겠습니다. 혼잡 제어 통계는 모두 nstat 명령어로 확인할 수 있고, node_exporter를 사용한다면 --collector.netstat, --collector.netstat.fields 옵션을 적절히 사용하여 수집할 수 있습니다.
재전송 관련 메트릭
TcpRetransSegs
재전송된 세그먼트 수입니다. 재전송은 네트워크 혼잡으로 인해 패킷이 유실되었다고 판단될 때 발생하지만, 네트워크 혼잡을 확인하기 위한 용도(TLP)로 발생할 수도 있습니다. 따라서 재전송 세그먼트가 있다고 해서 꼭 네트워크가 혼잡했다는 의미는 아닙니다.1 이 통계는 잘못 오해하기 쉬우므로 무시하는 것이 좋습니다.
TcpExtTCPSlowStartRetrans, TcpExtTCPFastRetrans
- TcpExtTCPSlowStartRetrans
The TCP stack wants to retransmit a packet and the congestion control state is ‘Loss’.
- TcpExtTCPFastRetrans
The TCP stack wants to retransmit a packet and the congestion control state is not ‘Loss’.
“SNMP Counter”, Linux Networking Documentation2
TcpExtTCPSlowStartRetrans는 TCP_CA_Loss 상태에서 발생한 재전송을, TcpExtTCPFastRetrans는 그 외 상태에서 발생한 재전송을 의미합니다. 단, TLP는 포함되지 않습니다. 따라서 이 두 통계는 네트워크 혼잡을 나타내는 좋은 지표입니다.
Recovery 관련 메트릭
TcpExtTCPRenoRecovery, TcpExtTCPSackRecovery
- TcpExtTCPRenoRecovery and TcpExtTCPSackRecovery
When the congestion control comes into Recovery state, if sack is used, TcpExtTCPSackRecovery increases 1, if sack is not used, TcpExtTCPRenoRecovery increases 1. These two counters mean the TCP stack begins to retransmit the lost packets.
“SNMP Counter”, Linux Networking Documentation
네트워크 혼잡을 감지하여 recovery 상태로 진입한 횟수입니다. SACK을 사용한다면 TcpExtTCPSackRecovery가 증가하고, 그렇지 않다면 TcpExtTCPRenoRecovery가 증가합니다.
TcpExtTCPLossProbeRecovery
TLP를 통해 네트워크 혼잡을 감지하여 recovery 상태로 진입한 횟수입니다.
Undo Recovery 관련 메트릭
TcpExtTCPFullUndo, TcpExtTCPPartialUndo, TcpExtTCPDSACKUndo, TcpExtTCPLossUndo
이전에 recovery를 수행하였지만 네트워크에 혼잡이 없었음을 발견하고 cwnd를 recovery 이전으로 다시 되돌린 횟수입니다. Recovery 수와 undo recovery 수가 거의 동일하다면 네트워크의 혼잡 보다는 패킷 순서가 뒤바뀌어 도착하는 등의 문제를 의심해보아야 합니다.
트레이싱
tcp_retransmit_skb
tcp_retransmit_skb 함수는 loss 혹은 recovery로 인해 세그먼트를 재전송할 때 실행됩니다. TLP로 인한 재전송은 tcp_send_loss_probe 함수에서 __tcp_retransmit_skb 함수를 호출하여 진행되며 tcp_retransmit_skb 함수를 호출하지 않습니다. 만약 TLP 재전송도 함께 모니터링하고 싶다면 tcp_retransmit_skb 함수 대신 __tcp_retransmit_skb 함수를 트레이싱해야 합니다.
tcp_retransmit_skb 혹은 __tcp_retransmit_skb 함수가 호출되었을 때의 네트워크 혼잡 상태를 알려면 inet_connection_sock의 icsk_ca_state 값을 참고하면 됩니다. 아래는 bpftrace로 구현된 tcpretrans.bt3를 약간 변형하여 재전송 당시 TCP 혼잡 상태를 출력하도록 만든 프로그램입니다.
#include <linux/socket.h>
#include <net/sock.h>
#include <net/inet_connection_sock.h>
BEGIN
{
@tcp_ca_states[0] = "OPEN";
@tcp_ca_states[1] = "DISORDER";
@tcp_ca_states[2] = "CWR";
@tcp_ca_states[3] = "RECOVERY";
@tcp_ca_states[4] = "LOSS";
}
kprobe:__tcp_retransmit_skb
{
$sk = (struct sock *)arg0;
$inet_family = $sk->__sk_common.skc_family;
if ($inet_family == AF_INET || $inet_family == AF_INET6) {
// initialize variable type:
$daddr = ntop(0);
$saddr = ntop(0);
if ($inet_family == AF_INET) {
$daddr = ntop($sk->__sk_common.skc_daddr);
$saddr = ntop($sk->__sk_common.skc_rcv_saddr);
} else {
$daddr = ntop(
$sk->__sk_common.skc_v6_daddr.in6_u.u6_addr8);
$saddr = ntop(
$sk->__sk_common.skc_v6_rcv_saddr.in6_u.u6_addr8);
}
$lport = $sk->__sk_common.skc_num;
$dport = $sk->__sk_common.skc_dport;
// Destination port is big endian, it must be flipped
$dport = ($dport >> 8) | (($dport << 8) & 0x00FF00);
$icsk = (struct inet_connection_sock *)arg0;
$ca_statestr = @tcp_ca_states[$icsk->icsk_ca_state];
time("%H:%M:%S ");
printf("%-8d %14s:%-6d %14s:%-6d %s\n", pid, $saddr, $lport,
$daddr, $dport, $ca_statestr);
}
}
END
{
clear(@tcp_ca_states);
}
출력 예시는 다음과 같습니다.
22:12:22 0 127.0.0.1:80 127.0.0.1:51322 LOSS // RTO로 인한 재전송을 의미합니다.
22:12:22 0 127.0.0.1:80 127.0.0.1:51322 RECOVERY // dup ACK, SACK 등으로 인한 재전송을 의미합니다.
22:12:22 0 127.0.0.1:80 127.0.0.1:51322 OPEN // TLP로 인한 재전송을 의미합니다.
아쉬운 점은 TLP 재전송의 경우, 네트워크 혼잡을 감지하였는지는 아직 알 수 없다는 점입니다. TLP는 ACK을 받은 후에야 tcp_process_tlp_ack 함수를 통해서 혼잡을 감지합니다.
또, TLP가 꼭 재전송을 통해서 진행되는 것이 아니기 때문에 __tcp_retransmit_skb 함수 트레이싱으로 보지 못하는 TLP도 있습니다. 따라서 tcp_retransmit_skb 혹은 __tcp_retransmit_skb 함수 트레이싱으로는 모든 네트워크 혼잡을 감지할 수는 없습니다.
tcp_set_ca_state
tcp_retransmit_skb함수 대신 tcp_set_ca_state 함수를 트레이싱하면 TCP의 혼잡 상태 변화를 감지하여 모든 네트워크 혼잡을 볼 수 있습니다.
#include <linux/socket.h>
#include <net/sock.h>
#include <net/inet_connection_sock.h>
kprobe:tcp_set_ca_state
{
$sk = (struct sock *)arg0;
$new_state = arg1;
$inet_family = $sk->__sk_common.skc_family;
if ($inet_family == AF_INET || $inet_family == AF_INET6) {
// initialize variable type:
$daddr = ntop(0);
$saddr = ntop(0);
if ($inet_family == AF_INET) {
$daddr = ntop($sk->__sk_common.skc_daddr);
$saddr = ntop($sk->__sk_common.skc_rcv_saddr);
} else {
$daddr = ntop(
$sk->__sk_common.skc_v6_daddr.in6_u.u6_addr8);
$saddr = ntop(
$sk->__sk_common.skc_v6_rcv_saddr.in6_u.u6_addr8);
}
$lport = $sk->__sk_common.skc_num;
$dport = $sk->__sk_common.skc_dport;
// Destination port is big endian, it must be flipped
$dport = ($dport >> 8) | (($dport << 8) & 0x00FF00);
$icsk = (struct inet_connection_sock *)arg0;
$old_state = $icsk->icsk_ca_state;
printf("%-8d %14s:%-6d %14s:%-6d %d -> %d\n", pid, $saddr, $lport,
$daddr, $dport, $old_state, $new_state);
}
}
출력 예시는 다음과 같습니다.
// OPEN 상태에서 DISORDER 상태로 변경되었습니다. 아마도 SACK을 수신했을 겁니다. 아직은 cwnd를 줄이지 않았습니다.
22:12:22 0 127.0.0.1:80 127.0.0.1:40956 0 -> 1
// DISORDER 상태에서 RECOVERY 상태로 변경되었습니다. Cwnd가 감소되었습니다.
22:12:22 0 127.0.0.1:80 127.0.0.1:40956 1 -> 3
// RECOVERY 상태에서 다시 OPEN 상태로 변경되었습니다.
22:12:22 0 127.0.0.1:80 127.0.0.1:40956 3 -> 0
// OPEN 상태에서 LOSS 상태로 변경되었습니다. RTO로 인한 재전송이 발생하였고 cwnd가 감소되었습니다.
22:12:22 0 127.0.0.1:80 127.0.0.1:40956 0 -> 4
리눅스 5.19 버전부터 tcp_set_ca_state tracepoint가 추가되었습니다4. 최신 버전 커널이라면 tracepoint를 사용하여 더 빠르고 안정적으로 트레이싱할 수도 있습니다.
echo 0 > /sys/kernel/debug/tracing/events/tcp/tcp_cong_state_set/enable
cat /sys/kernel/debug/tracing/trace
# tracer: nop
#
# entries-in-buffer/entries-written: 74/74 #P:1
#
# _-----=> irqs-off/BH-disabled
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / _-=> migrate-disable
# |||| / delay
# TASK-PID CPU# ||||| TIMESTAMP FUNCTION
# | | | ||||| | |
python3-24835 [000] ..s1. 29693.614116: tcp_cong_state_set: family=AF_INET sport=80 dport=49396 saddr=127.0.0.1 daddr=127.0.0.1 saddrv6=::ffff:127.0.0.1 daddrv6=::ffff:127.0.0.1 cong_state=3
python3-24835 [000] ..s1. 29693.614141: tcp_cong_state_set: family=AF_INET sport=80 dport=49396 saddr=127.0.0.1 daddr=127.0.0.1 saddrv6=::ffff:127.0.0.1 daddrv6=::ffff:127.0.0.1 cong_state=0
python3-24835 [000] ..s1. 29693.630122: tcp_cong_state_set: family=AF_INET sport=80 dport=49396 saddr=127.0.0.1 daddr=127.0.0.1 saddrv6=::ffff:127.0.0.1 daddrv6=::ffff:127.0.0.1 cong_state=1
python3-24835 [000] ..s1. 29693.630137: tcp_cong_state_set: family=AF_INET sport=80 dport=49396 saddr=127.0.0.1 daddr=127.0.0.1 saddrv6=::ffff:127.0.0.1 daddrv6=::ffff:127.0.0.1 cong_state=3
python3-24835 [000] ..s1. 29693.630154: tcp_cong_state_set: family=AF_INET sport=80 dport=49396 saddr=127.0.0.1 daddr=127.0.0.1 saddrv6=::ffff:127.0.0.1 daddrv6=::ffff:127.0.0.1 cong_state=0
tcp_sock의 snd_cwnd
tcp_sock 구조체의 snd_cwnd 필드에는 TCP 소켓의 현재 cwnd 값이 저장되어있습니다. 이를 모니터링하면 단순히 네트워크 혼잡 여부 뿐만 아니라, 혼잡으로 인해 TCP throughput이 얼마나 감소하였는지를 알 수 있습니다. BPF Performance Tools, Brendan Gregg(Addison-Wesley Professional, 2019)에 TCP cwnd를 모니터링하는 bpftrace 툴이 소개되었습니다. 5
아래 코드를 추가하면 현재 소켓을 통해 네트워크 상에 전송되고 있는 패킷 수 또한 함께 볼 수 있습니다.
$packets_out = $tcps->packets_out
...
위 툴로 cwnd와 packets_out을 출력하고 이를 그래프로 그려보면 다음과 같습니다.
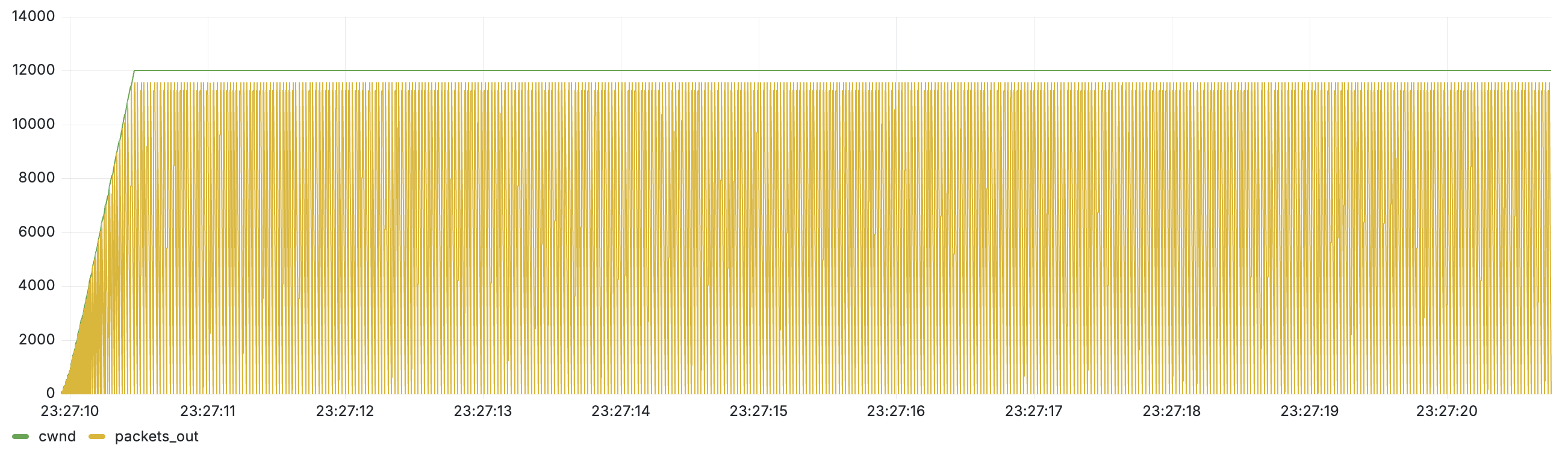 첫번째 그래프는 네트워크 혼잡이 없는 이상적인 경우입니다.
첫번째 그래프는 네트워크 혼잡이 없는 이상적인 경우입니다.
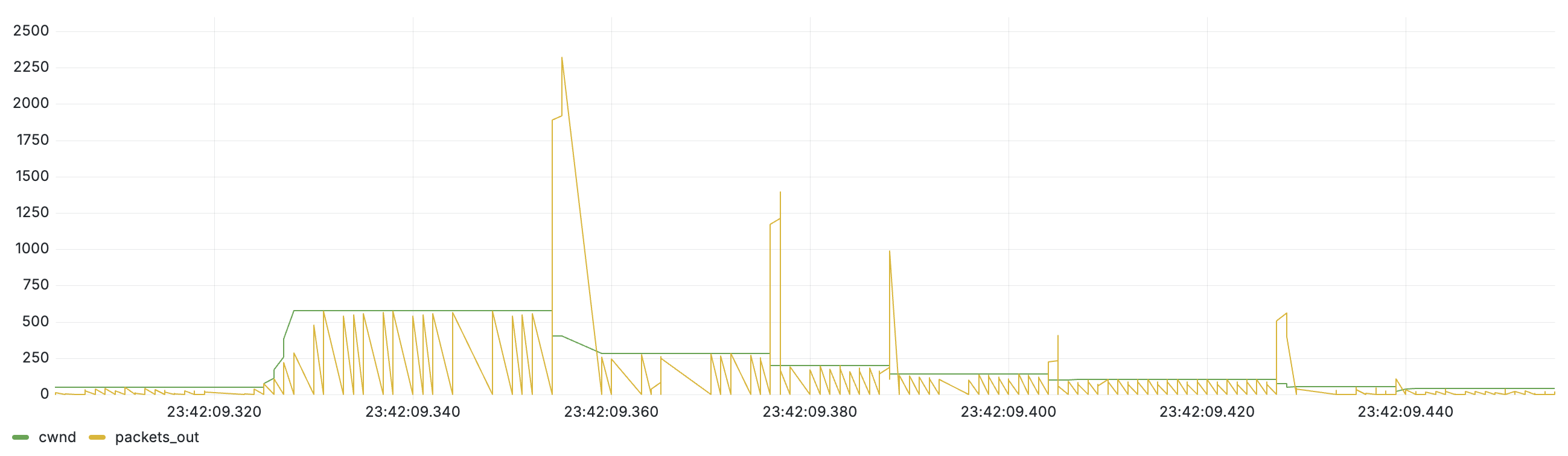 두번째 그래프는 네트워크에 혼잡이 있는 상황입니다. cwnd가 지속적으로 감소하고, packets_out이 cwnd 제한에 걸려 throughput이 낮아진 모습을 볼 수 있습니다.
두번째 그래프는 네트워크에 혼잡이 있는 상황입니다. cwnd가 지속적으로 감소하고, packets_out이 cwnd 제한에 걸려 throughput이 낮아진 모습을 볼 수 있습니다.
-
https://arthurchiao.art/blog/tcp-retransmission-may-be-misleading/ ↩
-
https://www.kernel.org/doc/html/v5.15/networking/snmp_counter.html ↩
-
https://github.com/bpftrace/bpftrace/blob/master/tools/tcpretrans.bt ↩
-
https://github.com/torvalds/linux/commit/15fcdf6ae116d1e8da4ff76c6fd82514f5ea501b ↩
-
https://github.com/brendangregg/bpf-perf-tools-book/blob/master/originals/Ch10_Networking/tcpwin.bt ↩