개요
서비스의 고가용성을 위해 일반적으로 로드밸런서 혹은 DNS를 사용합니다. 로드밸런서는 주기적으로 서버들에게 상태 검사 요청을 보내 문제가 있는 서버를 감지하고 자동으로 제외합니다. AWS의 Route 53과 같은 일부 DNS 솔루션도 이와 같은 기능을 제공합니다.
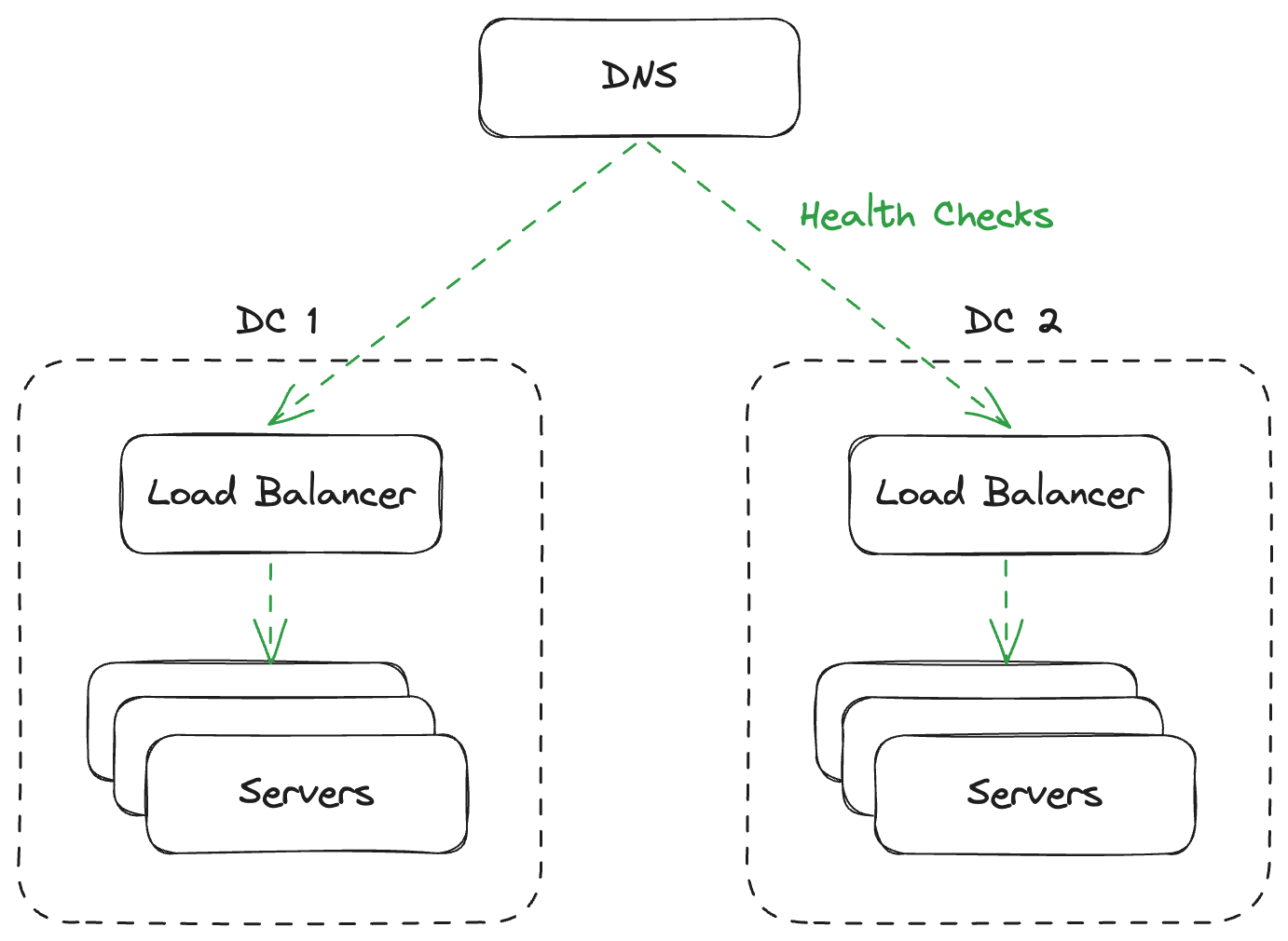
하지만 로드밸런서와 DNS가 문제를 감지하는 데에는 보통 몇 초 정도의 시간이 걸립니다. 예를 들어 로드밸런서가 각 서버로 3초마다 probe 요청을 보내고 연속하여 3번 이상 probe가 실패하였을 때 해당 서버를 제외한다면, 서버에 장애가 발생한 시점으로부터 약 9초에서 12초 후에 서버가 제외됩니다. 그동안은 장애가 지속될 수 있습니다. DNS가 로드밸런서 장애를 감지할 때도 마찬가지로 시간이 소요되며, 특히 DNS는 캐시 TTL이 있기 때문에 그만큼 문제 되는 인프라를 제외하는 데에 시간이 더 소요됩니다.
로드밸런서와 DNS가 문제를 감지하고 제외하는 동안 장애가 수 초 이상 지속될 수 있습니다. 이것이 대부분의 서비스에서는 큰 문제라고 생각하지 않을 수도 있지만, 몇몇 중요한 서비스에서는 큰 장애로 인식되기도 합니다. 그렇다면 어떻게 해야 장애 회복 시간을 줄일 수 있을지 한번 알아보겠습니다.
로드밸런서에서 장애 서버를 더 빨리 제외하기
첫 번째로 고려해 볼 방법은 로드밸런서에서 장애 서버를 더 빨리 제외하는 것입니다. 가장 쉬운 방법은 로드밸런서에서 probing 주기와 응답 대기 시간을 줄이는 것입니다. 하지만 시간을 너무 짧게 줄이면 오탐을 할 가능성이 커지기에 이 방법은 한계가 있습니다.
그 대신 로드밸런서가 서버의 응답 데이터를 보고 장애가 발생했는지 판단하는 방법이 있습니다. Probing을 보내는 방식이 아니라 서버의 실제 응답을 감시하는 방법이므로 순간적으로 장애가 발생하는 상황도 감지할 수 있습니다. 예를 들어 Envoy에서는 outlier detection1이라는 이름으로 이 기능을 제공합니다. 아래는 서버와 연결 실패나 timeout 오류가 5번 연속 발생하면 해당 서버를 제외하는 설정 예시입니다.
outlier_detection:
consecutive_local_origin_failure: 5
이 설정으로 장애 회복이 얼마나 빨라지는지 보기 위해 테스트를 해봤습니다. Envoy에 업스트림 서버 두 대를 구성하고 요청을 받던 중에 서버 한 대에서 프로세스를 강제로 종료했습니다. 아래는 outlier detection을 사용하지 않고 probing 만으로 서버 장애를 감지했을 때 결과입니다.
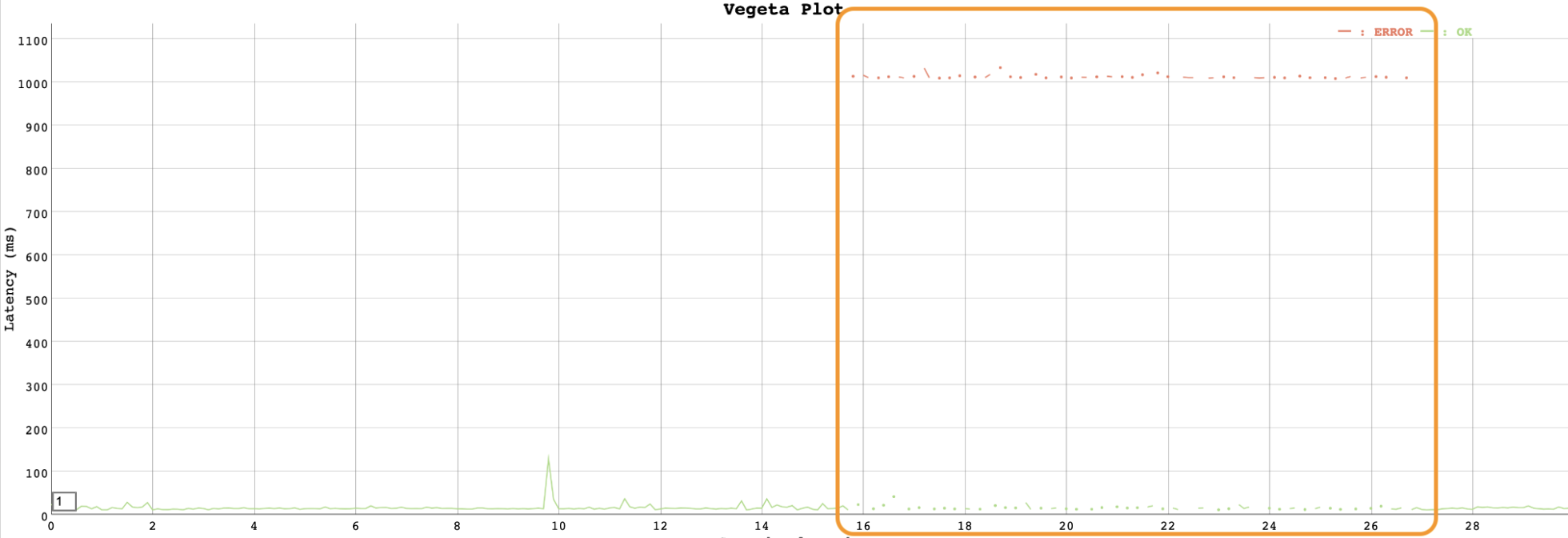
테스트 결과 약 10초 동안 절반의 요청이 실패한 모습을 볼 수 있습니다. 이 10초는 Envoy가 probing으로 서버 장애를 감지하는 데 걸린 시간입니다. 그 이후에는 서버가 제외되어 서비스가 정상화되었습니다.
이번에는 outlier detection을 적용한 후 동일한 테스트를 진행해 봤습니다.
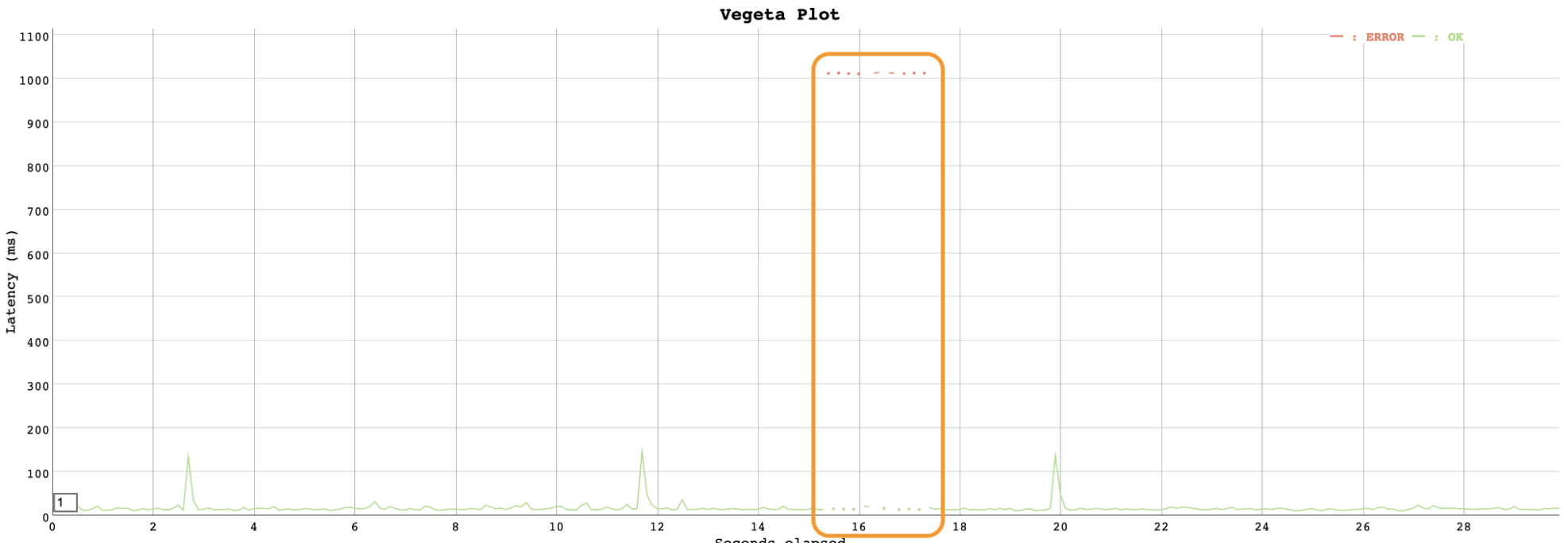
Outlier detection 적용 후에는 약 2초 만에 회복이 되었습니다. Probing 방식 보다 더 빠르게 장애를 감지하고 해소하는 걸 볼 수 있습니다.
재시도하기
다음으로 고려해 볼 방법은 서버로 보낸 요청이 실패할 시 재시도를 하는 것입니다. 재시도는 클라이언트에서 할 수도 있고 프록시(로드밸런서)에서 할 수도 있습니다.
예를 들어 Envoy에서는 retry policy2 설정을 통해 재시도 설정을 할 수 있습니다. 아래는 서버로 연결이 실패했을 때 다른 서버로 재시도를 하는 설정입니다. retry_host_predicates.previous_hosts 설정을 통해 이전에 요청이 실패한 서버를 기억하고, 다른 서버로 재시도를 하도록 했습니다.
retry_policy:
retry_on: connection-failure
retry_host_predicate:
- name: envoy.retry_host_predicates.previous_hosts
typed_config:
"@type": type.googleapis.com/envoy.extensions.retry.host.previous_hosts.v3.PreviousHostsPredicate
host_selection_retry_max_attempts: 3
Retry policy를 적용했을 때 테스트 결과는 다음과 같습니다.
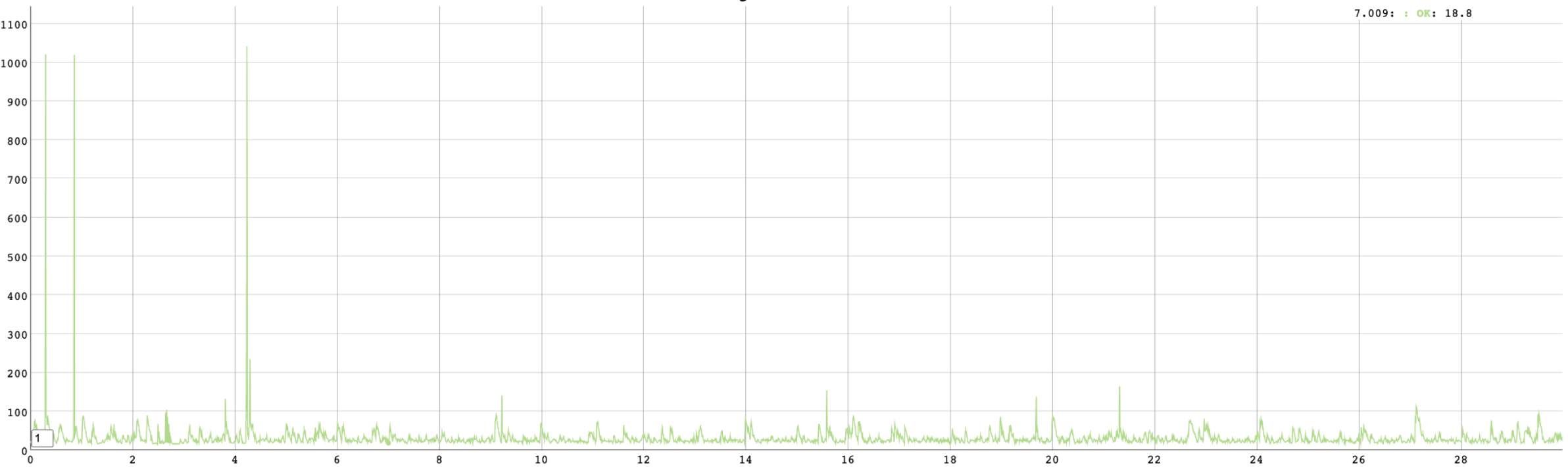
테스트 중간에 서버 한 대를 내렸음에도 불구하고 응답 실패가 전혀 발생하지 않은 걸 볼 수 있습니다.
다만 재시도를 할 때에는 주의해야 할 점들이 몇 가지 있습니다.
우선 RFC 9110에서는 프록시는 멱등하지 않은 요청은 절대 재시도하면 안 된다고 얘기합니다.3 하지만 어떤 요청이 멱등한지는 어플리케이션마다 다를 수 있으므로 로드밸런서에서는 이를 정확히 알기 어렵습니다.
9.2.2. Idempotent Methods
...
A proxy MUST NOT automatically retry non-idempotent requests.
또, 로드밸런서와 클라이언트가 동시에 재시도를 한다면 요청이 증폭되어 오히려 장애 상황을 악화시키는 문제도 있습니다.
따라서 재시도를 통해 효과적으로 장애 회복을 하기 위해서는 먼저 일관성 있는 정책이 필요합니다. 예를 들어 이런 정책을 세울 수 있습니다.
- 커넥션 오류 등으로 인해 요청 데이터를 전송하기 전에 실패한 경우에는 재시도를 합니다.
- HTTP 응답 코드가 502, 503, 504인 경우에는 요청을 재시도 합니다.
- 그 외 응답 코드인 경우에는 멱등한 요청만 재시도합니다. 백엔드 어플리케이션은 오류가 발생한 요청이 멱등함을 알리기 위해 응답 헤더에 특정 필드(예:
Allow-Retry: true) 추가합니다. 클라이언트 혹은 프록시는 실패한 요청의 응답 헤더에 해당 필드가 있다면 재시도를 합니다. 프록시에서 재시도를 하였다면 클라이언트에서도 중복으로 재시도를 하지 않게끔 응답 헤더에서 해당 필드를 제거합니다. - 그 외 경우에는 재시도를 하지 않습니다.
- Jitter와 exponential backoff를 사용하여 재시도 요청이 분산되도록 합니다.
DNS 다중 값 레코드 사용하기
DNS에서는 한 도메인에 여러 개의 레코드 값을 응답하는 것이 가능합니다. 예를 들어 aws.com은 아래와 같이 4개의 A 레코드를 응답하고 있습니다.
$ dig aws.com +noall +answer
aws.com. 60 IN A 18.64.8.60
aws.com. 60 IN A 18.64.8.26
aws.com. 60 IN A 18.64.8.45
aws.com. 60 IN A 18.64.8.50
가능하면 다중 값 레코드를 사용하는 것이 좋습니다. 그 이유는 다중 값 레코드가 클라이언트에게 더 많은 선택권을 주기 때문입니다.
만약 클라이언트가 aws.com 도메인에 대해 4개의 IP를 받았고 이 중 첫 번째 IP 주소인 18.64.8.60로 요청을 보냈지만 실패하였다면 다른 IP 주소인 18.64.8.26로 재시도를 해볼 수 있습니다. 반면 클라이언트가 aws.com 도메인에 대해 단 하나의 IP 주소만 받았고 그 IP 주소에 문제가 생겼다면, 클라이언트는 더 이상 할 수 있는 것이 없습니다.
다중 값 레코드의 효과를 테스트를 통해 확인해 보겠습니다.
먼저 단일 값 레코드를 사용할 때 IP 주소 중 하나에서 문제가 발생한 상황입니다.
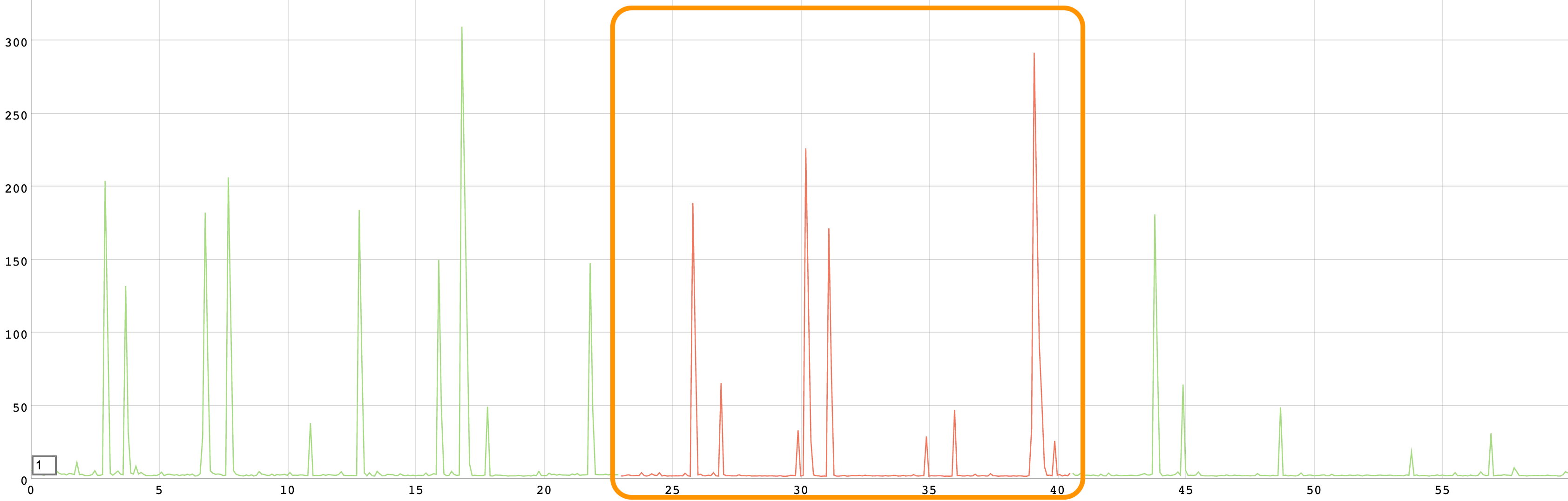
DNS 서버가 해당 IP를 probing 하여 문제가 있음을 감지하는 데에 약 10초가 소요되었고, 그 이후에 DNS TTL 만료되기까지 약 10초가 더 소요되어 약 20초 간 장애가 지속되었습니다. 그 이후에는 DNS가 문제 되는 IP 주소를 제외하여 해소된 모습입니다.
그럼 이번에는 다중 값 레코드를 사용할 때 결과를 보겠습니다.
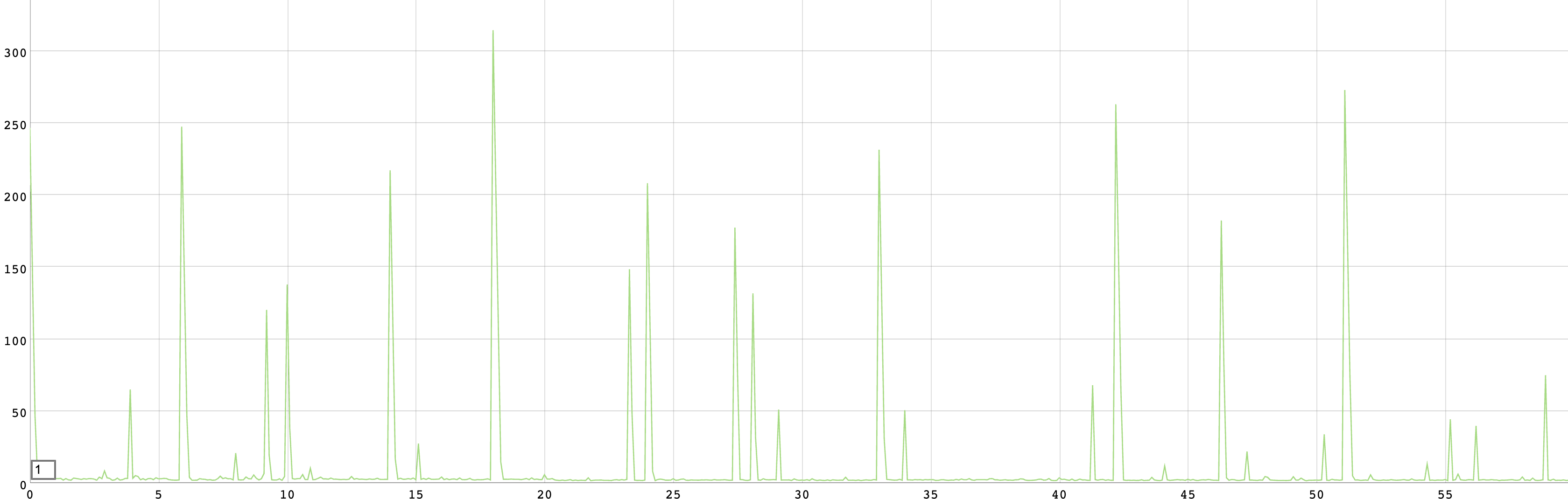
놀랍게도 요청이 모두 성공했습니다. 오류가 전혀 발생하지 않은 이유는 테스트에 사용한 vegeta 프로그램이 Go 언어로 구현되어 있는데, Go 언어에서 소켓 연결을 담당하는 Dial이 도메인 질의 결과로 여러 개의 IP 주소를 받으면 그중 한 IP 주소와 연결이 성공할 때까지 순차적으로 시도하기 때문입니다. 위 재시도하기 절에서 설명드린 커넥션 오류 등으로 인해 요청 데이터를 전송하기 전에 실패한 경우에는 재시도를 합니다가 이미 구현이 되어있는 셈입니다.
// go/src/net/dial.go
func (sd *sysDialer) dialSerial(ctx context.Context, ras addrList) (Conn, error) {
var firstErr error // The error from the first address is most relevant.
for i, ra := range ras {
// ...
c, err := sd.dialSingle(dialCtx, ra)
if err == nil {
return c, nil
}
if firstErr == nil {
firstErr = err
}
}
if firstErr == nil {
firstErr = &OpError{Op: "dial", Net: sd.network, Source: nil, Addr: nil, Err: errMissingAddress}
}
return nil, firstErr
}
이처럼 DNS 다중 값 레코드를 사용하면 클라이언트에서는 그중 한 IP 주소와만 통신을 하면 되기에 서비스 가용성이 더 높아집니다.
똑똑한 클라이언트 사용하기
위에서 설명드린 DNS 다중 값 레코드를 사용하더라도, 일부 클라이언트에서는 받은 IP 주소를 모두 사용하지 않기도 합니다. 가장 대표적인 예가 JDK의 HttpClient입니다.
아래는 JDK HTTPClient를 사용하여 다중 값 레코드를 갖고 있는 도메인에 요청을 보내는 코드입니다. DNS 레코드 중 하나는 통신이 불가능한 상태이고 다른 하나는 정상 통신이 가능한 상황이었지만 커넥션 오류가 발생하는 것을 볼 수 있습니다.
HttpClient client = HttpClient.newHttpClient();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(url))
.build();
client.send(request, HttpResponse.BodyHandlers.ofString());
Exception in thread "main" java.net.ConnectException
at java.net.http/jdk.internal.net.http.HttpClientImpl.send(HttpClientImpl.java:846)
at java.net.http/jdk.internal.net.http.HttpClientFacade.send(HttpClientFacade.java:123)
at org.example.Main.main(Main.java:23)
...
그 이유는 HttpClient가 도메인에 대한 IP 주소를 알아내기 위해 InetAddress.getByName 함수를 실행하는데,
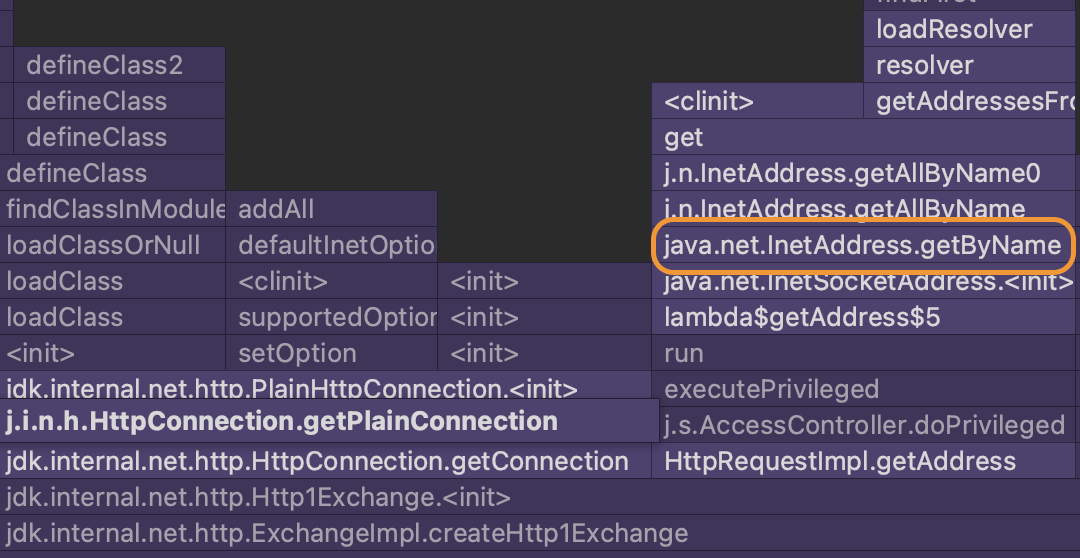
InetAddress.getByName 함수는 DNS 응답 레코드 중 첫 번째 IP 주소만 반환하기 때문입니다.
// java/net/InetAddress.java
public static InetAddress getByName(String host)
throws UnknownHostException {
return InetAddress.getAllByName(host)[0];
}
따라서 운 나쁘게 DNS 응답 레코드 중 첫번째 IP 주소에 문제가 생긴다면 다른 IP 주소에는 문제가 없더라도 요청이 바로 실패합니다.
심지어 이런 상황이 발생했을 때 클라이언트에서 요청을 여러번 재시도 하여도, DNS 응답이 캐싱되어 있다면 여전히 문제 되는 첫번째 IP 주소로만 요청을 보내고 실패하게 됩니다. 아래는 최대 5번 요청을 재시도했지만 DNS 캐싱으로 인해 문제 되는 IP 주소로만 통신을 시도하여 요청이 모두 실패한 모습입니다.
int MAX_RETRIES = 5;
for (int i = 0; i < MAX_RETRIES; i ++) {
try {
HttpClient client = HttpClient.newHttpClient();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(url))
.build();
client.send(request, HttpResponse.BodyHandlers.ofString());
System.out.println(response.body());
break;
} catch (Exception e) {
System.out.println(e);
}
}
java.net.ConnectException
java.net.ConnectException
java.net.ConnectException
java.net.ConnectException
java.net.ConnectException
이렇듯 모든 클라이언트가 좋은 장애 복구 동작을 하는 것은 아니므로 서비스에서 사용하는 네트워크 클라이언트는 문제 상황에서 어떻게 동작하는지 이해하는 것이 좋으며, 가능하면 똑똑하게 동작하는 클라이언트를 사용해야 합니다.