개요
패킷 재전송을 트레이싱 하는 건 많은 상황에서 유용하게 쓰일 수 있기에, 이를 쉽게 사용하게 하는 유저 영역 프로그램들이 이미 존재합니다. Ftrace로 구현된 것과 bpftrace, bcc로 구현된 것들이 있습니다.
이 중 Ftrace를 사용하여 구현한 perf-tools 프로젝트의 tcpretrans는 이 툴들의 원조로, 10년 전에 작성되었지만 여전히 유용합니다. Bpftrace와 bcc 기반 툴을 사용하기 위해서는 여러 의존 패키지들을 설치해야 하지만, perf-tools의 tcpretrans는 의존성 없이 스크립트 파일 하나만으로 바로 실행이 가능하다는 장점이 있습니다. 또, eBPF를 지원하지 않는 예전 버전의 커널에서도 잘 동작합니다.
그러나 perf-tools의 tcpretrans는 오래전에 만들어진 만큼 예전 방식으로 구현되어 있습니다. 이로 인해 커넥션이 매우 많은 서버에서는 성능 문제가 생길 수도 있습니다.
perf-tools tcpretrans의 성능 문제
네트워크 부하 상황을 만들어 tcpretrans 툴의 성능을 측정해보겠습니다.
서버에서 8만 개의 TCP 소켓을 만들고, 주기적으로 SYN 세그먼트를 재전송하는 상황을 만들었습니다. 매 초 약 2만 개의 세그먼트가 재전송되었습니다.
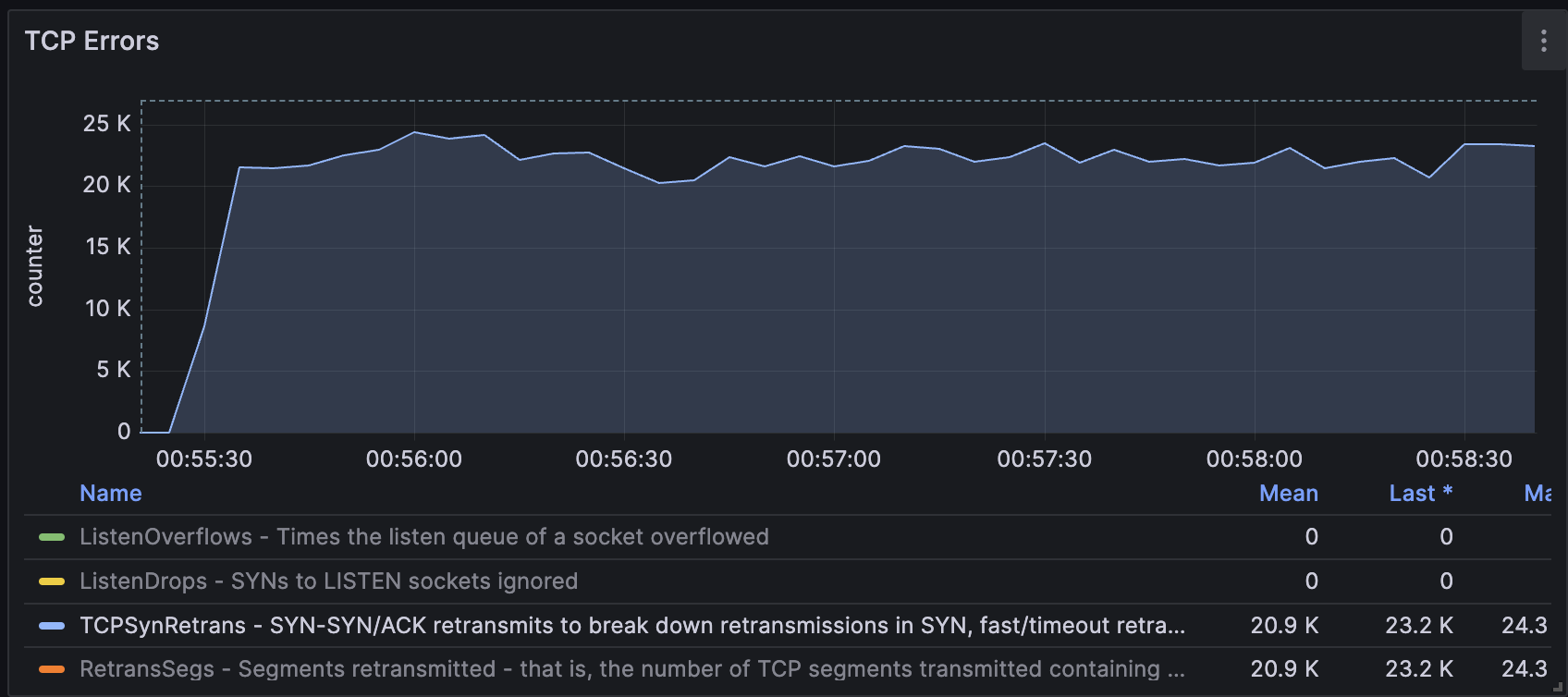
부하를 주는 중간에 tcpretrans 툴을 실행시켰습니다. 아래 그래프는 tcpretrans를 실행시키기 전후 CPU 사용량 추이입니다. tcpretrans를 실행시킨 후 CPU 사용률이 약 2~30% 정도 증가했습니다.
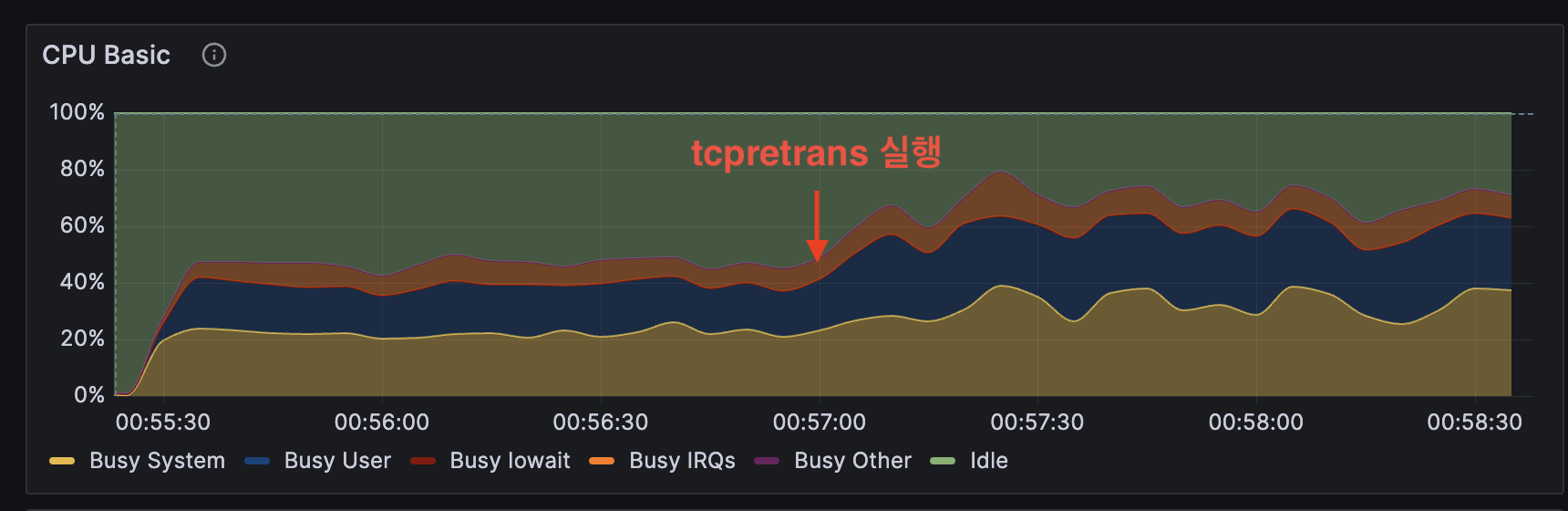
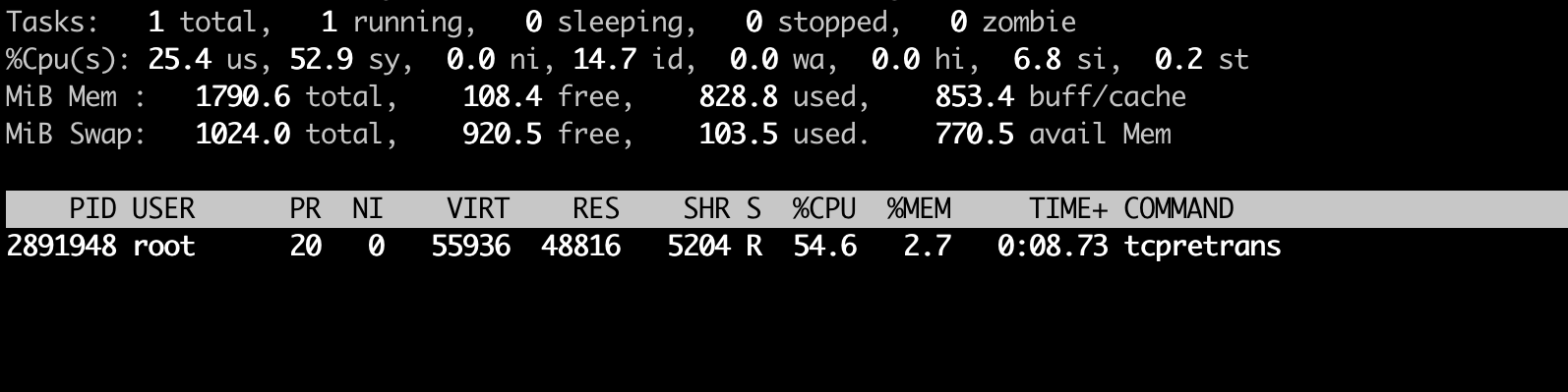
이때 tcpretrans의 CPU 사용량을 보면 약 50% 정도를 사용 중인 것을 볼 수 있습니다. 이는 결코 작지 않은 수치입니다.
왜 pert-tools의 tcpretrans 툴은 이렇게 많은 CPU 리소스를 사용하는지 tcpretrans 구현을 살펴보며 알아보겠습니다.
perf-tools tcpretrans 동작 방식과 그로 인한 한계
이런 성능 문제가 발생하는 이유는 tcpretrans 스크립트에서 /proc/net/tcp를 매초 읽기 때문입니다.
sub cache_tcp {
undef %tcp;
open(TCP, "/proc/net/tcp") or ldie "ERROR: reading /proc/net/tcp.";
while (<TCP>) {
next if /^ *sl/;
my ($sl, $local_address, $rem_address, $st, $tx_rx, $tr_tm,
$retrnsmt, $uid, $timeout, $inode, $jf, $sk) = split;
$sk =~ s/^0x//;
$tcp{$sk}{laddr} = $local_address;
$tcp{$sk}{raddr} = $rem_address;
$tcp{$sk}{state} = $st;
}
close TCP;
}
/proc/net/tcp는 TCP 소켓 별 정보를 제공합니다. 때문에 소켓 수가 매우 많다면, /proc/net/tcp 파일을 읽을 때 성능 문제가 발생할 수 있습니다. tcpretrans와 비슷하게 /proc/net/tcp를 주기적으로 읽는 node_exporter의 tcpstat 콜렉터 설명에는 이런 경고 문구가 적혀있습니다.1
Exposes TCP connection status information from /proc/net/tcp and /proc/net/tcp6.
(Warning: the current version has potential performance issues in high load situations.)
그럼 왜 perf-tools의 tcpretrans는 /proc/net/tcp 파일을 읽을까요?
tcpretrans는 커널의 tcp_retransmit_skb 함수를 트레이싱 하는데, perf-tools가 만들어졌을 당시에는 tracepoint에 tcp_retransmit_skb 함수가 없었기에 그 대신 kprobe를 사용하여 구현되었습니다. perf-tools가 만들어진 지 4년이 지난 후에야, tcp_retransmit_skb 함수가 커널 4.15 버전에서 tracepoint에 추가되었습니다.2
좀 더 자세한 상황을 이해하기 위해 tracepoint를 사용하여 tcp_retransmit_skb를 트레이싱했을 때와 kprobe를 사용하여 트레이싱했을 때를 비교해 보겠습니다.
tracepoint 사용
아래 명령어로 tracepoint event를 트레이싱합니다.
$ echo 1 > /sys/kernel/debug/tracing/events/tcp/tcp_retransmit_skb/enable
트레이싱 결과를 확인해 보면 다음과 같습니다. 엔드포인트 IP 주소, 포트, TCP 상태 등 원하는 모든 정보가 출력됩니다.
$ cat /sys/kernel/debug/tracing/trace
...
<idle>-0 [001] ..s. 33959779.477843: tcp_retransmit_skb: sport=80 dport=61270 saddr=10.0.0.1 daddr=10.0.0.2 saddrv6=::ffff:10.0.0.1 daddrv6=::10.0.0.2 state=TCP_ESTABLISHED
이 출력 포멧은 커널에서 관리되는 안정적인 API입니다. 커널 버전이 바뀌더라도 원하는 정보들을 얻을 수 있다는 게 보장됩니다.
$ cat /sys/kernel/debug/tracing/events/tcp/tcp_retransmit_skb/format
...
print fmt: "sport=%hu dport=%hu saddr=%pI4 daddr=%pI4 saddrv6=%pI6c daddrv6=%pI6c state=%s", REC->sport, REC->dport, REC->saddr, REC->daddr, REC->saddr_v6, REC->daddr_v6, __print_symbolic(REC->state, { TCP_ESTABLISHED, "TCP_ESTABLISHED" }, { TCP_SYN_SENT, "TCP_SYN_SENT" }, { TCP_SYN_RECV, "TCP_SYN_RECV" }, { TCP_FIN_WAIT1, "TCP_FIN_WAIT1" }, { TCP_FIN_WAIT2, "TCP_FIN_WAIT2" }, { TCP_TIME_WAIT, "TCP_TIME_WAIT" }, { TCP_CLOSE, "TCP_CLOSE" }, { TCP_CLOSE_WAIT, "TCP_CLOSE_WAIT" }, { TCP_LAST_ACK, "TCP_LAST_ACK" }, { TCP_LISTEN, "TCP_LISTEN" }, { TCP_CLOSING, "TCP_CLOSING" }, { TCP_NEW_SYN_RECV, "TCP_NEW_SYN_RECV" })
kprobe 사용
이제 kprobe를 사용하여 같은 함수를 트레이싱 해보겠습니다. tcp_retransmit_skb 함수의 인자인 소켓의 메모리 주솟값을 %di 레지스터에 저장하도록 합니다.
$ echo "p:kprobes/tcpretrans_tcp_retransmit_skb tcp_retransmit_skb sk=%di" > cat /sys/kernel/debug/tracing/kprobe_events
트레이싱 결과를 확인해 보면 tracepoint를 사용했을 때와는 다르게 IP 주소, 포트 등의 정보는 없고 소켓의 메모리 주솟값만 알 수 있습니다.
$ cat /sys/kernel/debug/tracing/trace_pipe
<idle>-0 [000] ..s. 33956923.137285: tcpretrans_tcp_retransmit_skb: (tcp_retransmit_skb+0x0/0xc0) sk=0xffff8ab718c808c0
kprobe를 통해서 소켓의 IP 주소, 포트 등을 출력하도록 할 수도 있습니다. 하지만 그러려면 소켓 구조체 필드들의 메모리 상대 주솟값을 계산해가며 원하는 데이터를 얻어야 하는데, 이것이 쉽지 않을뿐더러 커널 버전이 바뀜에 따라 구조체가 달라질 수 있다는 문제도 있습니다.
perf-tools 제작자인 Brendan도 이런 이유로 자세한 소켓 정보를 kprobe로 가져오는 것 대신에, /proc/net/tcp에서 읽어오는 것을 선택했습니다.3 그 당시에는 이것이 최선의 선택이었을 겁니다.
So, it was a gift to have socket details in /proc/net/tcp, and not need to dig them out using ftrace.
That would be possible, but the script would become much more brittle without kernel debuginfo,
as there would then be several assumptions about registers and struct offsets, rather than just skb being in %di.
/proc/net/tcp 파일에는 소켓 별 엔드포인트 IP 주소, 포트, TCP 상태 정보와 소켓의 메모리 주솟값이 있습니다.
$ cat /proc/net/tcp
sl local_address rem_address st tx_queue rx_queue tr tm->when retrnsmt uid timeout inode
5: 0100000A:0000 0200000A:0000 02 00000001:00000000 01:00000617 00000005 2015 0 384729917 2 ffff8ab718c808c0 3200 0 0 1 -1
perf-tools는 kprobe로 알아낸 재전송이 발생한 소켓의 주솟값을 이 파일에서 찾아 소켓의 상세 정보를 출력하였습니다.
/proc/net/tcp 파일에서 소켓의 정보를 읽어오기 때문에 perf-tools의 tcpretrans는 소켓이 많아지면 성능 문제가 발생합니다.
또, 가끔씩 아래처럼 재전송 세그먼트 정보가 보이지 않는 경우가 있습니다.
$ sudo ./tcpretrans
TIME PID LADDR:LPORT -- RADDR:RPORT STATE
01:06:59 0 -:- R> -:- -
01:07:08 0 -:- R> -:- -
소켓이 빨리 닫혀 /proc/net/tcp를 읽을 때 이미 정보가 사라진 경우이거나, 컨테이너를 사용하여 분리된 /proc 파일 시스템이 있는 환경이라면 이렇게 패킷 정보를 볼 수 없습니다.
tracepoint를 사용하여 개선
perf-tools의 tcpretrans가 가진 여러 문제들은 tracepoint를 사용하면 모두 해결됩니다.
kprobe 대신 tracepoint를 사용하도록 개선한 코드는 여기에서 보실 수 있습니다. tracepoint를 사용하면서 /proc/net/tcp를 읽는 부분이 삭제되었습니다.
성능 재측정
위에서 진행한 성능 테스트를 개선된 스크립트로 다시 진행해 보겠습니다.
이번에는 tcpretrans 스크립트를 실행하여도 CPU 사용량이 증가하지 않았습니다.
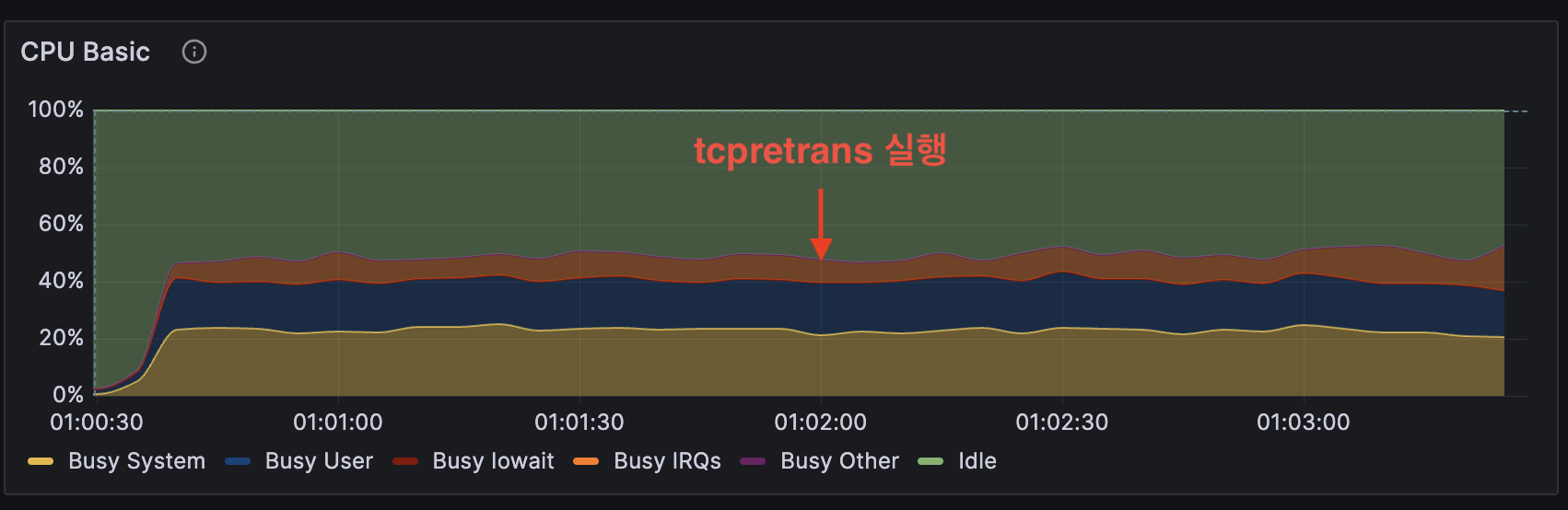
tcpretrans 스크립트의 CPU 사용량이 1% 미만으로, 오버헤드가 매우 개선되었음을 확인할 수 있습니다!
또한 이전 버전의 스크립트와는 달리 TCP 소켓 정보를 /proc/net/tcp에서 읽지 않고 tracepoint 출력에서 가져오므로, 재전송된 패킷 정보를 놓치는 일도 없어졌습니다.
아쉬운 점
하지만 아쉽게도 개선된 스크립트가 완벽한 것은 아닙니다. tcp_retransmit_skb tracepoint는 사실 tcp_retransmit_skb 함수가 아니라 __tcp_retransmit_skb 함수 안에 들어가 있습니다.
int __tcp_retransmit_skb(struct sock *sk, struct sk_buff *skb, int segs)
{
struct inet_connection_sock *icsk = inet_csk(sk);
// ...
if (likely(!err)) {
trace_tcp_retransmit_skb(sk, skb);
} else if (err != -EBUSY) {
NET_ADD_STATS(sock_net(sk), LINUX_MIB_TCPRETRANSFAIL, segs);
}
return err;
}
문제는 __tcp_retransmit_skb 함수가 tail loss probe로 인해 재전송될 때도 실행된다는 점입니다.
void tcp_send_loss_probe(struct sock *sk)
{
// ...
if (__tcp_retransmit_skb(sk, skb, 1))
goto rearm_timer;
// ...
}
따라서 tcp_retransmit_skb tracepoint로 트레이싱을 하면 TLP로 인한 재전송도 함께 보입니다. TLP는 네트워크에 문제가 없어도 자주 발생할 수 있기 때문에, 트레이싱 결과 만으로는 실제로 패킷 유실이 있었는지 판단하기 어려워집니다.
이땐 nstat 명령어 결과 중 TcpExtTCPLossProbes 통계 값을 함께 봐야합니다. 트레이싱에 재전송된 패킷이 잡힘과 동시에 TcpExtTCPLossProbes 값이 증가했다면 그 패킷은 TLP로 인해 재전송된 것이었을 겁니다.
혹은 ftrace에서 stacktrace를 출력하는 기능을 켜 어떤 함수에서 __tcp_retransmit_skb가 실행되었는지 확인할 수도 있습니다.
$ echo 1 > /sys/kernal/tracing/options/stacktrace
아래는 RTO로 인한 재전송이 일어났을 때 트레이싱 결과입니다. tcp_retransmit_timer 함수에서 __tcp_retransmit_skb 함수가 호출된 걸 볼 수 있습니다.
$ cat /sys/kernel/tracing/trace
...
<idle>-0 [000] ..s. 30957243.308751: tcp_retransmit_skb: sport=44656 dport=80 saddr=10.61.245.172 daddr=10.0.0.1 saddrv6=::ffff:10.61.245.172 daddrv6=::ffff:10.0.0.1 state=TCP_SYN_SENT
<idle>-0 [000] ..s. 30957243.308760: <stack trace>
=> __tcp_retransmit_skb
=> tcp_retransmit_skb
=> tcp_retransmit_timer
...
아래는 TLP로 인한 재전송이 일어났을 때 트레이싱 결과입니다. tcp_send_loss_probe 함수에서 __tcp_retransmit_skb 함수가 호출되었습니다.
$ cat /sys/kernel/tracing/trace
...
<idle>-0 [000] ..s. 30958394.579659: tcp_retransmit_skb: sport=8080 dport=33818 saddr=172.18.0.3 daddr=172.18.0.4 saddrv6=::ffff:172.18.0.3 daddrv6=::ffff:172.18.0.4 state=TCP_CLOSING
<idle>-0 [000] ..s. 30958394.579665: <stack trace>
=> __tcp_retransmit_skb
=> tcp_send_loss_probe
...
기존 kprobe 기반 tcpretrans 스크립트에서는 -l 옵션을 통해 TLP 재전송도 함께 트레이싱할지를 선택할 수 있었지만 tracepoint를 사용한 구현에서는 이를 구분하기 까다로운 점은 아쉽습니다.
따라서 만약 TLP로 인한 재전송은 트레이싱에서 제외하고 싶고 기존 perf-tools의 tcpretrans를 사용하기에는 성능 문제가 우려된다면, eBPF를 사용하는 것을 고려해야 합니다.